一、研究背景
房地产市场作为经济活动的关键领域之一,对于经济的发展和社会的稳定起着至关重要的作用。在当今全球化和信息化的背景下,房地产市场的波动和房价的变化不仅受到国内因素的影响,还受到全球经济环境和国际政治形势等外部因素的影响。因此,准确预测房价成为了政府、企业和个人都极为关注的重要问题。
二、研究意义
本研究旨在利用机器学习模型对房价进行预测,探索不同模型在房价预测任务上的性能差异,并通过优化最佳模型提高预测准确性。具体来说,本研究的意义体现在以下几个方面:为房价预测提供新方法。传统的房价预测方法受限于模型复杂度和特征提取能力,而机器学习模型能够更好地利用大规模数据,挖掘潜在的规律和趋势,为房价预测提供了新的方法和思路。提高决策的准确性和可靠性。。。。
三、研究方案
本研究将借助机器学习技术,利用大量的房屋数据和相关特征,建立起一个有效的房价预测模型。通过对比不同机器学习模型的性能以及对最佳模型的进一步优化,旨在提高房价预测的准确性和可靠性,为相关利益方提供更加有效的决策支持,推动房地产市场的健康发展和经济的持续稳定。。。
四、国内外研究现状
从国内研究来看,随着我国经济快速发展和城市化的不断推进,我国房地产市场日新月异,中国的房地产市场一直快速增长,价格预测已经成为人们和决策者的一个重要问题。崔慧莹主要是通过改进极端随机森林模型对大连市二手房屋价格进行预测,本文的创新点为提出一种基于卡方先验的混合特征选择算法的极端随机森林(GSR-ERF)模型,提出基于Hyperopt超参数优化方法来对GSR-ERF模型进行参数寻优。本文的研究工作主要包括以下几个方面:首先,本文的数据集使用python语言爬取房产超市2022年大连市二手房屋数据,将爬取的数据进行数据预处理、数据清洗等工作,对数据清洗后的二手房屋数据进行缺失值填补、标准化处理,最后对二手房屋数据进行分析描述。其次,本文提出一种基于先验卡方原理的混合特征选择算法的极端随机森林模型(GSR-ERF模型),该算法分别得出基于遗传算法、模拟退火算法、交叉验证递归消除法的最优特征子集,并通过先验测试集分别得到这三种模型在先验测试集上的卡方分数。随后通过这三种模型的卡方占比结合其对应的最优特征子集对其进行排序得到最终的最优特征子集,最终通过得到的最优特征子集训练极端随机森林模型[1]。
五、实证分析
数据和代码
报告代码数据
本文的数据是爬取的昆明市的房价网站的数据,爬取完为文本数据,所以还需要对原始数据进行预处理,最终数据处理完成图如下:
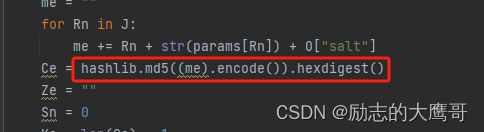
data = pd.read_csv('data (2).csv',encoding='GBK')
其中特征具体细节如下表:
| 解释 | 类型 |
| 房屋的卧室数量(个) | 连续值 |
| 房屋的客厅数量(个) | 连续值 |
| 房屋面积(平方米) | 连续值 |
| 房屋朝向 | 离散值,1=东;2=南;3=西;4=北;5=东南;6=东北;7=西北;8=西南 |
| 房屋装修情况 | 离散值,0=其他;1=毛坯;2=简装;3=精装 |
| 建筑结构 | 离散值,0=其他;1=板楼;2=塔楼;3=板塔结合;4=平房 |
| 房屋所在楼层位置 | 离散值,0=低楼层;1=中楼层;2=高楼层 |
| 关注度(人次) | 连续值 |
| 房屋发布时长 | 连续值 |
| 附近是否有地铁 | 离散值,0=否;1=是 |
| 是否可以VR看房 | 离散值,0=否;1=是 |
| 每平方米价格(元) | 连续值 |
其中特征为11个,“每平方米价格(元)”为响应变量。整体数据为2992条。接下来对数据进行描述性统计分析:
# Performing descriptive statistics on the dataset
descriptive_stats = data.describe()
# Display the descriptive statistics
descriptive_stats| 房屋卧室数量 | 房屋客厅数量 | 房屋面积 | 房屋朝向 | 房屋装修情况 | 建筑结构 | 房屋所在楼层位置 | |
| count | 2992 | 2992 | 2992 | 2992 | 2992 | 2992 | 2992 |
| mean | 3.451203 | 1.904412 | 134.988189 | 3.340241 | 2.148061 | 1.486631 | 1.036430 |
| std | 1.078478 | 0.461367 | 76.563728 | 2.089092 | 1.081347 | 0.918524 | 0.782419 |
| min | 1.000000 | 0.000000 | 25.070000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 3.000000 | 2.000000 | 92.000000 | 2.000000 | 1.000000 | 1.000000 | 0.000000 |
| 50% | 3.000000 | 2.000000 | 122.000000 | 2.000000 | 3.000000 | 1.000000 | 1.000000 |
| 75% | 4.000000 | 2.000000 | 146.815000 | 5.000000 | 3.000000 | 2.000000 | 2.000000 |
| max | 9.000000 | 5.000000 | 1220.600000 | 8.000000 | 3.000000 | 4.000000 | 2.000000 |
| 关注度(人次) | 房屋发布时长 | 附近是否有地铁 | 是否可以VR看房 | 每平方米价格 | |
| count | 2992 | 2992 | 2992 | 2992 | 2992 |
| mean | 3.478275 | 7.752564 | 0.321190 | 0.984960 | 12832.349265 |
| std | 11.983001 | 4.083428 | 0.467012 | 0.121733 | 5417.981420 |
| min | 0.000000 | 0.060000 | 0.000000 | 0.000000 | 3921.000000 |
| 25% | 0.000000 | 3.000000 | 0.000000 | 1.000000 | 9811.750000 |
| 50% | 1.000000 | 9.000000 | 0.000000 | 1.000000 | 11548.000000 |
| 75% | 3.000000 | 12.000000 | 1.000000 | 1.000000 | 14463.750000 |
| max | 514.000000 | 12.000000 | 1.000000 | 1.000000 | 65279.000000 |
从表中可以看到,在房屋属性方面,房屋卧室数量平均约为3.45,客厅数量平均约为1.90,说明多数房屋有3到4个卧室和1到2个客厅。房屋面积的平均约为134.99平方米,标准差较大,说明房屋面积的分布相对较广,最小值为25.07平方米,最大值为1220.60平方米。。。。
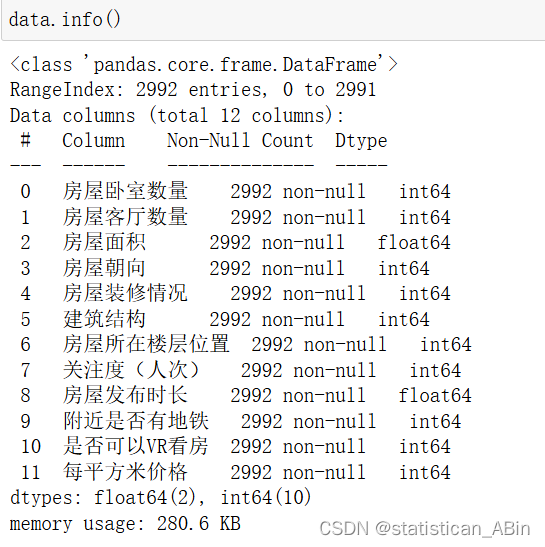
整数型数据:房屋的卧室数量、客厅数量、房屋朝向、装修情况、建筑结构、房屋所在楼层位置、关注度、附近是否有地铁、是否可以VR看房以及每平方米价格都是整数型数据。
接下来对数据预处理之后查看是否仍然存在缺失值的情况:

接下来数据可视化及其分析
首先查看一下每平方米价格与房屋面积的关系
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10, 6),dpi=200)
sns.scatterplot(x=data['房屋面积'], y=data['每平方米价格'])
plt.title('每平方米价格与房屋面积的关系')
plt.xlabel('房屋面积(平方米)')
plt.ylabel('每平方米价格')
plt.show()
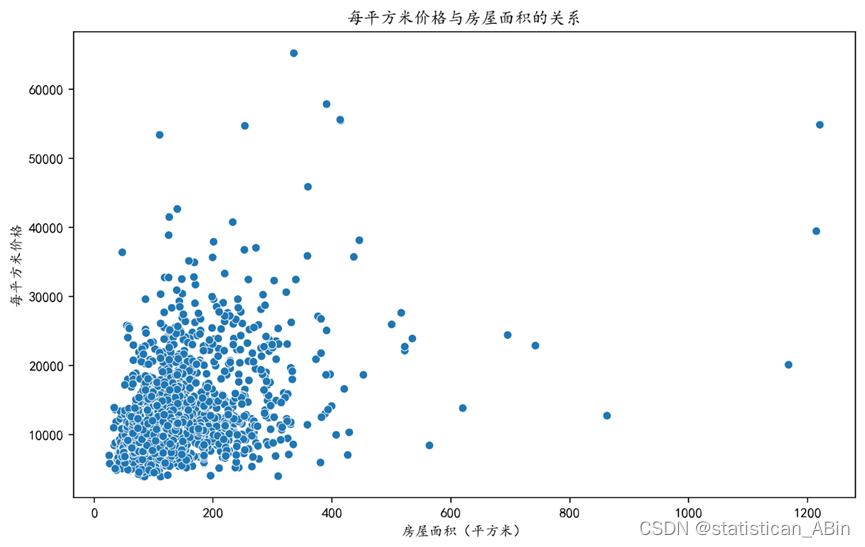
从散点图中可以看到,横轴标记的是“房屋面积(平方米)”,纵轴标记的是“每平方米价格”,大部分数据都分布在0-200的房屋面积(平方米)类,而且其房价均很高。
接下来价格与卧室数量的关系图:
plt.figure(figsize=(10, 6), dpi=200)
sns.boxplot(x=data['房屋卧室数量'], y=data['每平方米价格'])
plt.title('每平方米价格与卧室数量的关系')
plt.xlabel('卧室数量')
plt.ylabel('每平方米价格')
plt.show()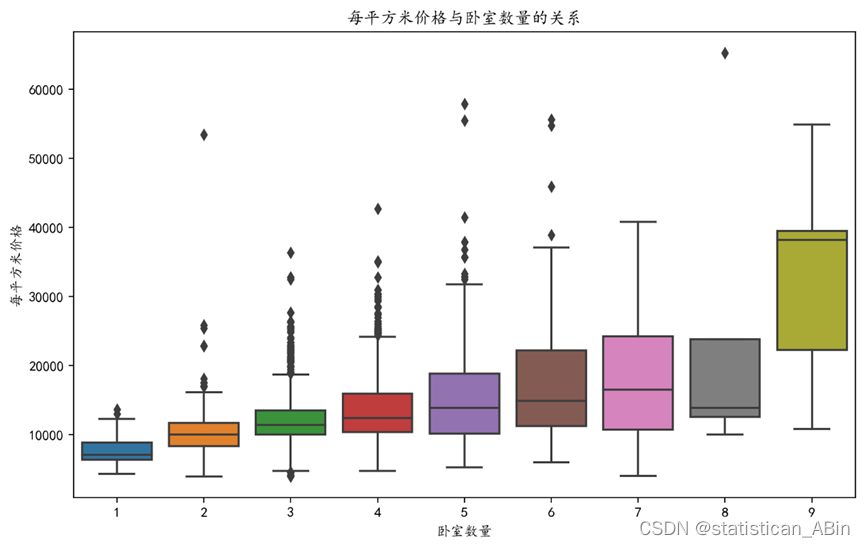
接下来是价格与附近是否有地铁的关系图
plt.figure(figsize=(10, 6),dpi=200)
sns.boxplot(x=data['附近是否有地铁'], y=data['每平方米价格'])
plt.title('附近是否有地铁与每平方米价格的关系')
plt.xlabel('附近是否有地铁')
plt.ylabel('每平方米价格')
plt.show()
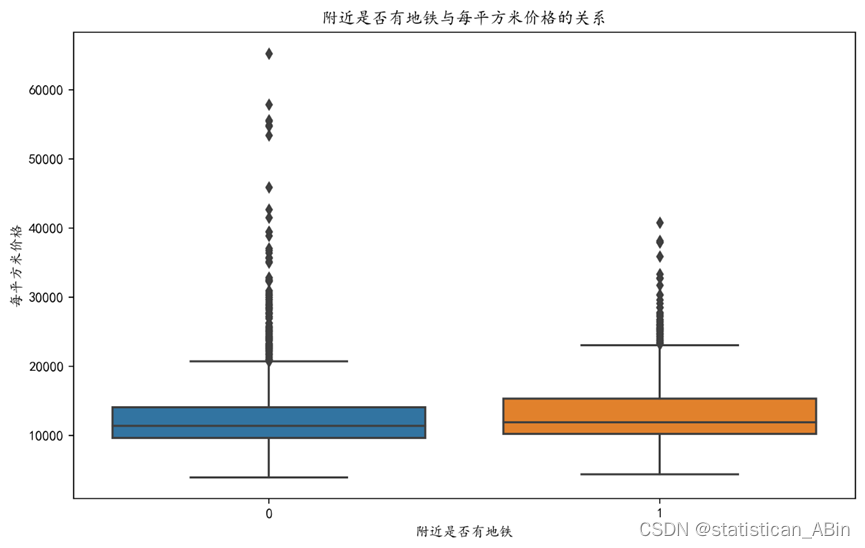 上图图中有两个箱形图,一个表示没有地铁的情况(标记为“0”),另一个表示有地铁的情况(标记为“1”)。从图中可以看到,附近有地铁站的箱形图(“1”)中位数似乎高于没有地铁站的(“0”),这通常是市场上的常态,因为地铁站的便利通常会提高房产价值。。
上图图中有两个箱形图,一个表示没有地铁的情况(标记为“0”),另一个表示有地铁的情况(标记为“1”)。从图中可以看到,附近有地铁站的箱形图(“1”)中位数似乎高于没有地铁站的(“0”),这通常是市场上的常态,因为地铁站的便利通常会提高房产价值。。
价格与房屋朝向的关系图
plt.figure(figsize=(10, 6), dpi=200)
sns.boxplot(x=data['房屋朝向'], y=data['每平方米价格'])
plt.title('每平方米价格与房屋朝向的关系')
plt.xlabel('房屋朝向')
plt.ylabel('每平方米价格')
plt.show()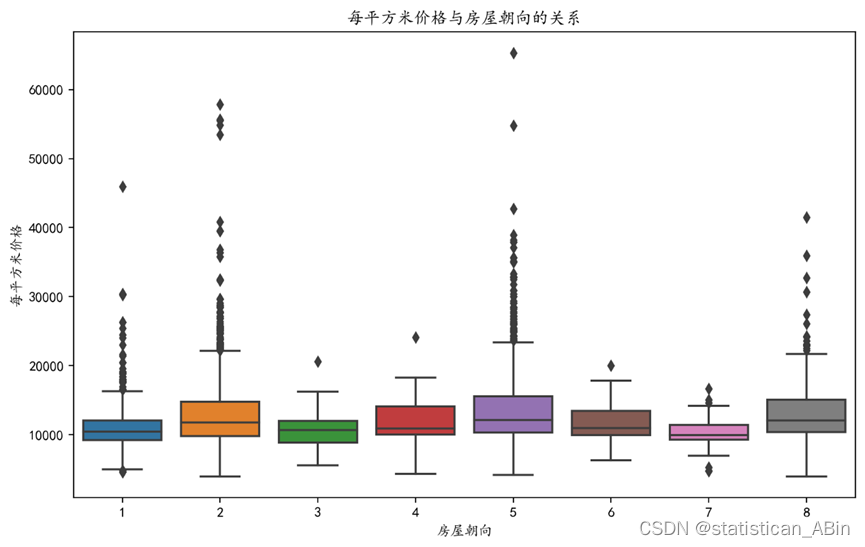
通过分析上图,可以得出一个初步结论:房屋的朝向对于房价的影响似乎相对较小。尽管如此,我们可以观察到一些趋势,例如,东南朝向的房屋往往拥有更高的价格,
接下来查看房屋装修情况的分布
 从直方图上可以看到:“其他”装修类型的房屋(标记为0)的数量最少,这可能意味着市场上此类房屋的供应较少。“毛坯”房屋(标记为1)的数量适中,暗示有一定市场,但不是最常见的类型。。。。
从直方图上可以看到:“其他”装修类型的房屋(标记为0)的数量最少,这可能意味着市场上此类房屋的供应较少。“毛坯”房屋(标记为1)的数量适中,暗示有一定市场,但不是最常见的类型。。。。
接下来查看房屋装修情况占比
data = pd.read_csv('data2.csv',encoding="gbk")
plt.rcParams['font.sans-serif'] = ["Fangsong"]
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(12,6),dpi=200)
figure,axes = plt.subplots(1,1,figsize = (6,6),dpi = 120)
y = [344,528,461,1659]
label=["其他", "毛坯", "简装", "精装"]
# 绘图
plt.pie(y,
labels=label, #
autopct='%.2f%%',
labeldistance = 1.1,
pctdistance = 0.9,
# shadow = True,
radius = 1,
startangle = 90,
counterclock = False
)
plt.title("房屋装修情况占比",fontsize = 12)
具体来看,饼图中占据最大比例的是红色部分,标记为“精装”,占比为55.45%,这说明超过半数的房源是精装修的。精装通常意味着房源在交付时装修完成,包括地板、厨卫设施、墙面处理等,买家可以直接入住,无需再进行大规模装修。
接下来查看楼层分布情况
plt.rcParams['font.sans-serif'] = ["Fangsong"]
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(12,6),dpi=200)
figure,axes = plt.subplots(1,1,figsize = (6,6),dpi = 120)
y = [863,1157,972]
label=["低楼层", "中楼层", "高楼层"]
plt.pie(y,
labels=label,
autopct='%.1f%%',
labeldistance = 1.1,
pctdistance = 0.9,
# shadow = True,
radius = 1,
startangle = 90,
counterclock = False
)
plt.title("楼层分布",fontsize = 12)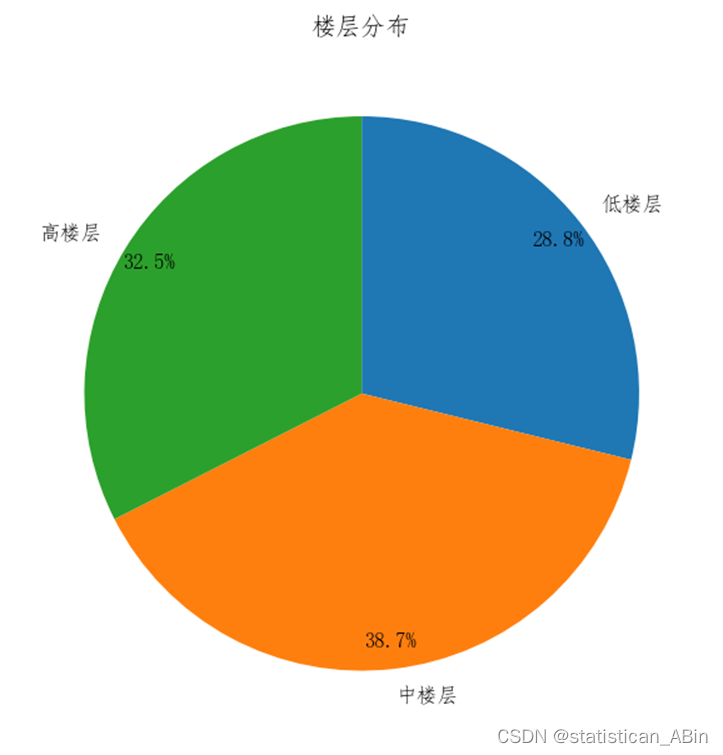
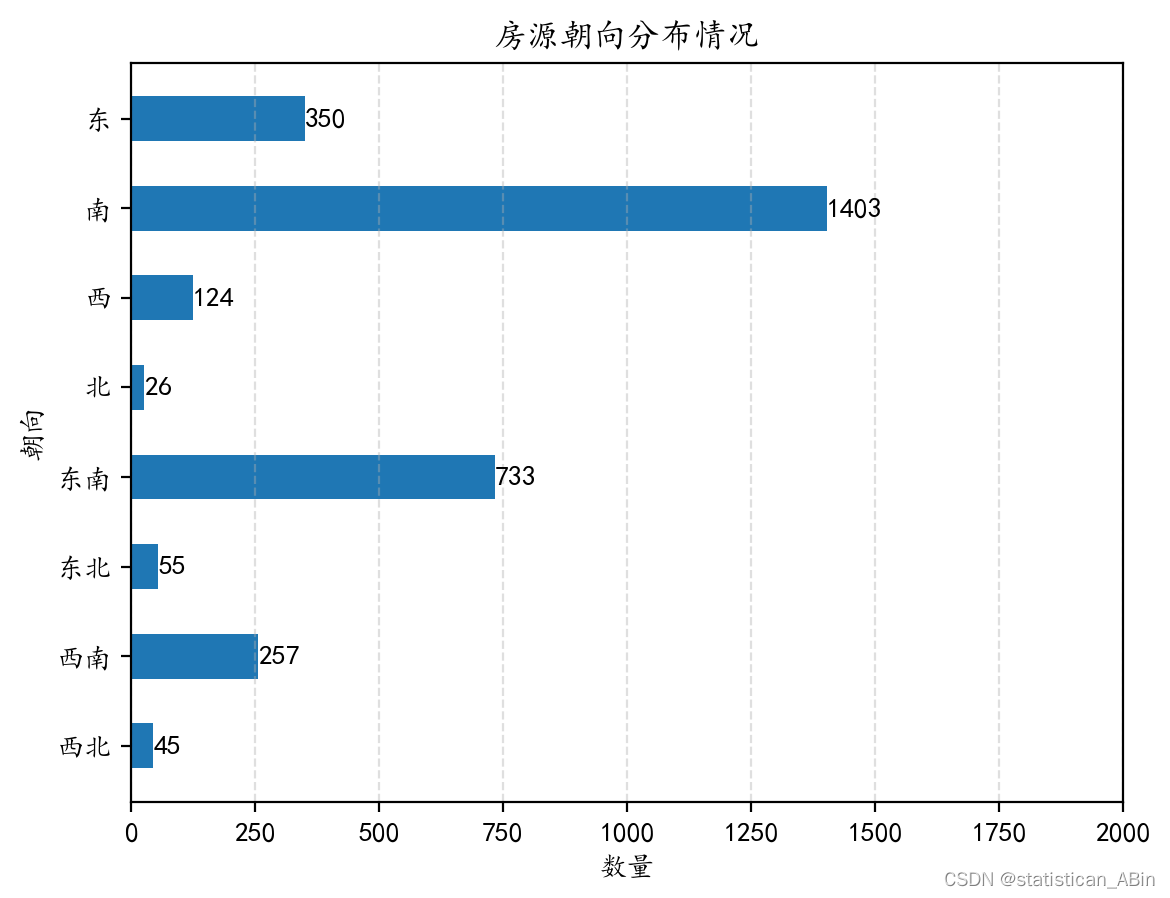
这张水平条形图显示了不同朝向的房源数量分布。每个条形代表一个朝向,条形的长度表示该朝向房源的数量。
具体来看,图中显示了七个不同的朝向类别:“南”朝向的房源数量最多,共有1403个。
接下来查看相关性热力图
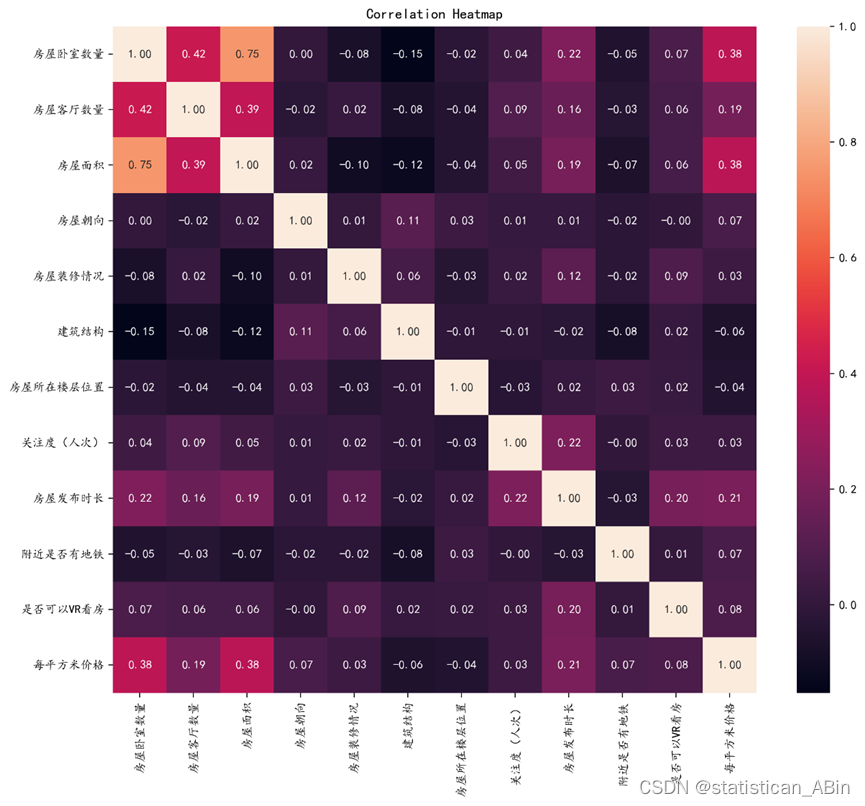 在这个热力图中,每个格子的颜色深浅表示了相关性的强度,颜色越接近红色表示正相关越强,越接近紫色表示正相关越弱。白色或接近白色的格子则表示很强的相关性。“房屋面积”与“单价”之间也有很强的正相关(0.38),这是合理的,因为在一点程度下,面积越大单价越高。
在这个热力图中,每个格子的颜色深浅表示了相关性的强度,颜色越接近红色表示正相关越强,越接近紫色表示正相关越弱。白色或接近白色的格子则表示很强的相关性。“房屋面积”与“单价”之间也有很强的正相关(0.38),这是合理的,因为在一点程度下,面积越大单价越高。
接下来开始机器学习
from sklearn.neighbors import KNeighborsRegressor
#K近邻
model1 = KNeighborsRegressor(n_neighbors=10)
model1.fit(X_train_s, y_train)
model1.score(X_val_s, y_val)
# 在验证集上进行预测
y_pred_KNN = model1.predict(X_val_s)
# 计算性能指标
mae_rf = mean_absolute_error(y_val, y_pred_KNN)
rmse_rf = mean_squared_error(y_val, y_pred_KNN, squared=False)
mape_rf = np.mean(np.abs((y_val - y_pred_KNN) / y_val)) * 100
r2_rf = r2_score(y_val, y_pred_KNN)
#随机森林
model2= RandomForestRegressor(n_estimators=500, max_features=int(X_train.shape[1]/3) , random_state=0)
model2.fit(X_train_s, y_train)
model2.score(X_val_s, y_val)# 计算性能指标
mae_rf = mean_absolute_error(y_val, y_pred_rf)
rmse_rf = mean_squared_error(y_val, y_pred_rf, squared=False)
mape_rf = np.mean(np.abs((y_val - y_pred_rf) / y_val)) * 100
r2_rf = r2_score(y_val, y_pred_rf)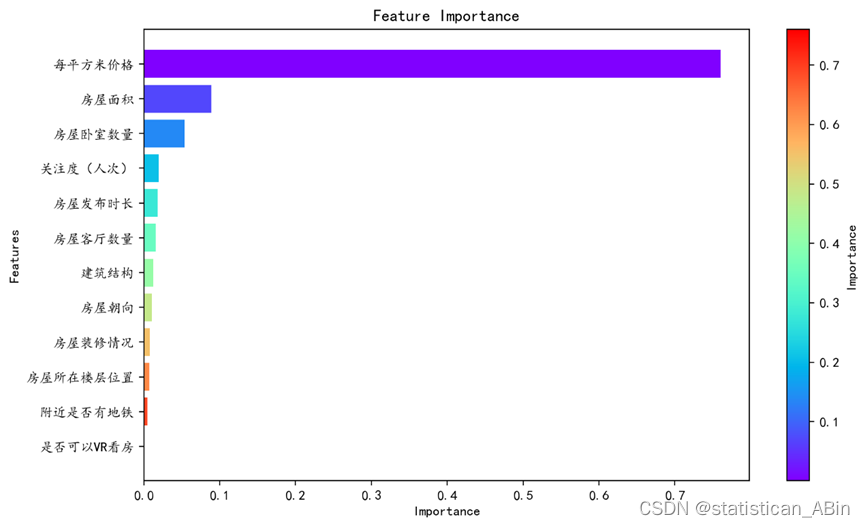
特征的重要性如下:
“每平方米价格”远远高于其他特征,重要性接近0.7,这意味着它对房价的预测影响最大,这也是很直观的体现。“房屋面积”是第二重要的特征,其重要性约为0.2,也对房价有显著的影响。。。。
接下来查看模型比较
| 模型 | MAE | RMSE | MAPE | R2 |
| KNN | 1515.515 | 2036.733 | 13.326 | 0.863 |
| 随机森林 | 278.045 | 1087.203 | 2.259 | 0.961 |
| 梯度提升 | 29.968 | 62.850 | 0.219 | 0.998 |
# 创建两个子图,分别绘制MAE和RMSE的柱状图,以及MAPE和R²分数的折线图
fig, axes = plt.subplots(2, 1, figsize=(10, 10),dpi=200)
# 绘制MAE和RMSE的柱状图
axes[0].bar(models, mae_scores, color='blue', label='MAE')
axes[0].bar(models, rmse_scores, color='green', label='RMSE', alpha=0.5)
axes[0].set_ylabel('Error')
axes[0].set_title('MAE and RMSE Comparison')
axes[0].legend()
# 绘制MAPE和R²分数的折线图
axes[1].plot(models, mape_r2_scores, marker='o', color='green', label='MAPE')
axes[1].plot(models, [0.863, 0.961, 0.999], marker='o', color='purple', label='R^2')
axes[1].set_ylabel('Score')
axes[1].set_title('MAPE and R^2 Score Comparison')
axes[1].legend()
# 自动调整布局
plt.tight_layout()
# 展示图表
plt.show()
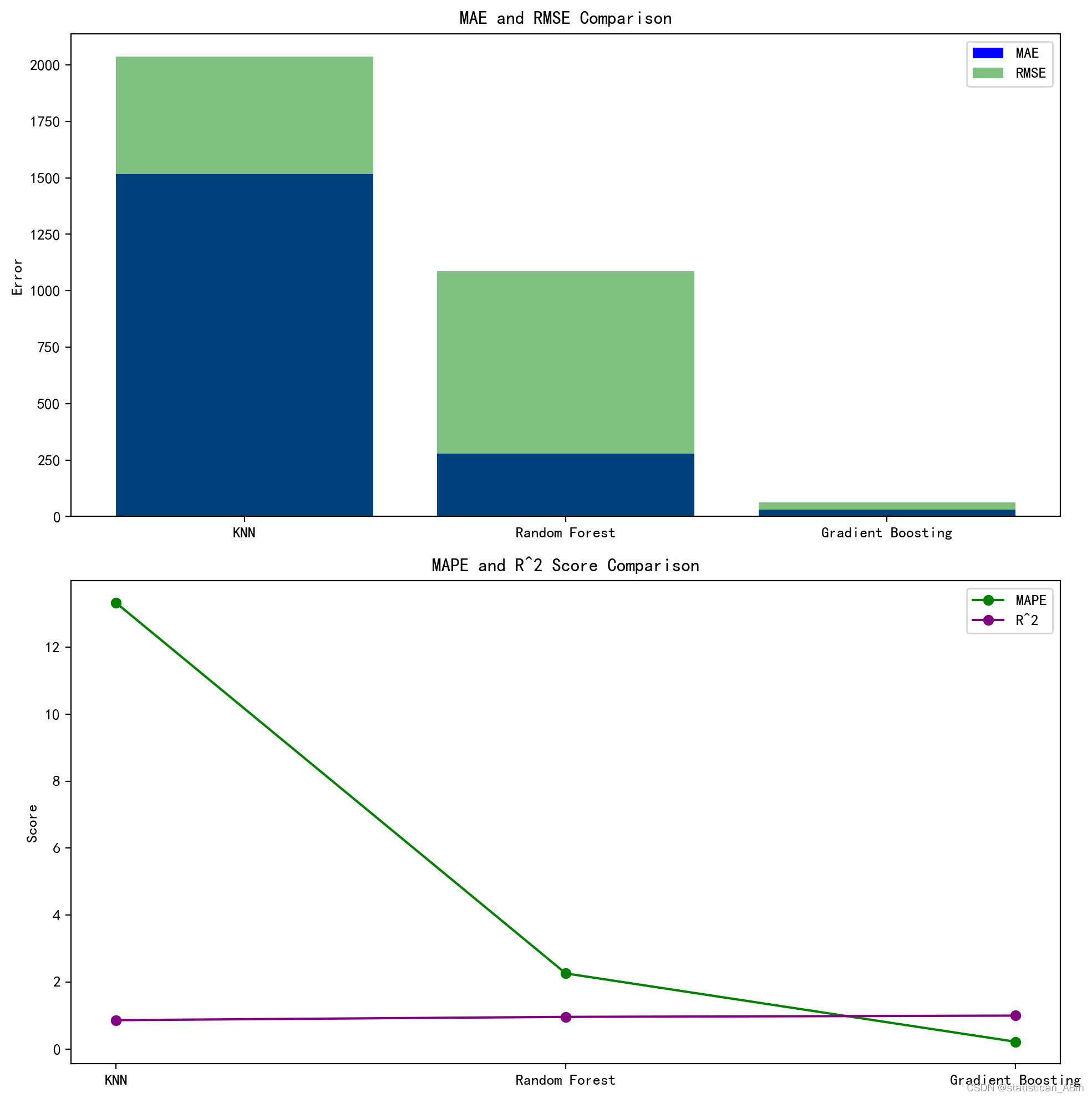
这个直方图展示了三种不同机器学习模型:KNN(K最近邻),随机森林,和梯度提升在两个误差度量标准上的表现,即平均绝对误差(MAE)和均方根误差(RMSE)。KNN模型的MAE和RMSE都显著高于其他两种模型,这表明在这个特定任务中KNN的性能最差。
接下来进行模型优化
在优化过程中使用了网格搜索交叉验证(Grid Search Cross-Validation)来调整随机森林模型的超参数,以获得最佳模型性能。
# Parameters to tune
param_grid = {
'n_estimators': [100, 200, 300],
'max_features': ['auto', 'sqrt', 'log2'],
'max_depth': [10, 20, 30, None],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# Grid search with cross-validation
rf = RandomForestRegressor(random_state=42)
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=3, n_jobs=-1, verbose=2)
# Fitting the grid search model
grid_search.fit(X_train, y_train)
# Best parameters
best_params = grid_search.best_params_
best_params| 模型 | MAE | RMSE | MAPE | R2 |
| RF | 281.05 | 1134.93 | 3.5432 | 0.9379 |
六、结论与展望
通过对昆明市房价数据的深入分析和建模,我们得出了一系列重要结论:
首先,朝向对房价的影响相对较小,尽管存在一些趋势,如东南朝向的房价相对较高,但整体影响不明显。在模型对比方面,最终梯度提升模型的拟合优度和其他误差效果是最好的,但是也不排除是过拟和的情况,在随机森林重要性特征方面,特征重要性分析显示每平方米价格是最为显著的影响因素。。。
参考文献
[1]崔慧莹. 基于极端随机森林算法的改进与二手房价预测的研究[D].大连交通大学,2023.DOI:10.26990/d.cnki.gsltc.2023.000640.
[2]张慧如.群优化GBDT复合模型的房价预测研究[D].山西大学,2023.DOI:10.27284/d.cnki.gsxiu.2023.001225.
创作不易,希望大家多点赞关注评论!!!(类似代码或报告定制可以私信)